ニューラルネットワークの書き方
PyTorchでニューラルネットワークを書いてみましょう。この章の目的は、全体の流れがどのようになるのかを掴む事です。それぞれのモジュールの詳細はあとで詳しく説明します。
手始めに 手書き数字のデータセットであるMNISTを認識させてみましょう。MNISTに含まれている数字を描画すると以下のようになります。この画像がどの数字なのかを当てるのが今回の問題です。
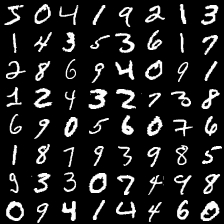
PyTorchのコードは以下のようになります。同じコードは、https://github.com/convergence-lab/Entering-PyTorch/blob/master/src/about_pytorch/mnist/mnist.pyから入手できます。
from tqdm import tqdm
import torch
from torch import nn, optim
import torch.nn.functional as F
from torchvision import datasets, transforms
class Net(nn.Module):
"""Net Module
MNISTを学習するためのネットワーク
"""
def __init__(self):
"""__init__ではNetworkの初期化をする。
どのようなレイヤを使うのかを定義する
"""
super(Net, self).__init__()
self.base_net = nn.Sequential( # base_netは特徴分析用のネットワーク
nn.Conv2d(1, 20, 5, 1), # Conv2Dレイヤ
nn.ReLU(), # ReLU活性化関数
nn.MaxPool2d(2), # maxpoolingレイヤ
nn.Conv2d(20, 40, 5, 1), # Conv2Dレイヤ
nn.ReLU() # ReLU活性化関数
)
self.classfier = nn.Sequential( # classifierは分類用のネットワーク
nn.Linear(40*8*8, 100), # Linearレイヤ、 40*8*8ユニットの入力を受けて、 100ユニットを出力する
nn.ReLU(), # ReLU活性化関数
nn.Linear(100, 10), # Linearレイヤ MNISTは 10この数字を当てる問題なので出力は10ユニット
nn.LogSoftmax() # LogSoftmaxレイヤ
)
def forward(self, x):
"""forwardでは、どのようにデータをネットワークに通すかを書く
"""
x = self.base_net(x) # base_netへ特徴を通す
x = x.view(-1, 40*8*8) # base_netと classifierでは入力テンソルの形が違うので変形する
x = self.classfier(x) # classifierへ通す
return x
def train(model, device, train_loader, optimizer, criterion, epoch):
"""
学習用の関数
"""
model.train() # Networkを学習モードにする
train_loss = 0
for batch in tqdm(train_loader):
data, target = batch # batchからデータとターゲットを取り出す
data, target = data.to(device), target.to(device) # デバイスへデータを転送
optimizer.zero_grad() # 勾配の情報をゼロにリセット
pred = model(data) # ネットワークにデータを入れる
loss = criterion(pred, target) # 損失を計算
loss.backward() # 勾配を計算
optimizer.step() # ネットワークを更新
train_loss += loss.item() # 損失を記録
print(f"Epoch {epoch}: Train loss {train_loss / len(train_loader)}")
def test(model, device, test_loader, criterion, epoch):
"""
評価用の関数
評価用の関数では、学習と違い、optimizerが不要
"""
model.eval() # ネットワークを評価モードに
test_loss = 0
correct = 0
for batch in tqdm(test_loader):
with torch.no_grad():
data, target = batch
data, target = data.to(device), target.to(device)
pred = model(data)
loss = criterion(pred, target)
test_loss += loss.item()
correct += pred.argmax(dim=1).eq(target).sum().item() # 正解率を計算
print(f"Epoch {epoch}: Test loss {test_loss / len(test_loader)}, Accuracy {100. * correct / len(test_loader.dataset)} %")
def main():
"""
main関数
"""
torch.manual_seed(0) # シードを固定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # CUDAが利用できるなrあ利用する
epoch = 5
batch_size = 100
save_model = False
# 学習データを読み込む
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../../../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# 評価データを読み込む
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../../../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
model = Net().to(device) # ネットワークをデバイスへ転送
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adamオプティマイザを利用する
criterion = nn.NLLLoss() # 損失関数は、負の対数尤度関数
# 学習用ループ
for ep in range(epoch):
# 学習する
train(model, device, train_loader, optimizer, criterion, ep)
# 評価する
test(model, device, test_loader, criterion, ep)
if save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
if __name__ == "__main__":
main()
プログラムを実行するには、以下のようにコマンドを入力します。
python mnist.py
100%|████████████████████████████████████████████| 600/600 [00:37<00:00, 16.31it/s]
Epoch 0: Train loss 0.15002354049279043
100%|████████████████████████████████████████████| 100/100 [00:02<00:00, 38.75it/s]
Epoch 0: Test loss 0.052312903378624466, Accuracy 98.26 %
(省略)
Epoch 4: Test loss 0.030565274948021397, Accuracy 99.19 %
学習の結果、Accuracy(正解率)は 99.19 %になりました。 以下の章で、このコードがどのようなコードなのかを理解するための解説を始めます。
main関数
まず、main関数をみてみましょう。
def main():
"""
main関数
"""
torch.manual_seed(0) # シードを固定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # CUDAが利用できるなら利用する
epoch = 5
batch_size = 100
save_model = False
# 学習データを読み込む
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../../../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# 評価データを読み込む
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../../../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
model = Net().to(device) # ネットワークをつくりデバイスへ転送
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adamオプティマイザを利用する
criterion = nn.NLLLoss() # 損失関数は、負の対数尤度関数
# 学習用ループ
for ep in range(epoch):
# 学習する
train(model, device, train_loader, optimizer, criterion, ep)
# 評価する
test(model, device, test_loader, criterion, ep)
if save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
次の部分では、MNISTデータの読み込みを行っています。データを持っていない場合は、ダウンロードされます。
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../../../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# 評価データを読み込む
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../../../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
以下の部分で、学習に必要なものを用意しています。用意するのは次の3つです。
- model
- ニューラルネットワークの本体です。
- optimizer
- ニューラルネットワークの学習方法です
- criterion
- 正解データとニューラルネットワークの出力の誤差の計算方法です。これをちいさくする事が学習の目的になります。
model = Net().to(device) # ネットワークをつくりデバイスへ転送
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adamオプティマイザを利用する
criterion = nn.NLLLoss() # 損失関数は、負の対数尤度関数
実際に学習を回しているのは次のループです。epoch回だけ学習を繰り返します。すべての学習データを1回ずつ学習を終えると、1 epoch学習したと数えます。
# 学習用ループ
for ep in range(epoch):
# 学習する
train(model, device, train_loader, optimizer, criterion, ep)
# 評価する
test(model, device, test_loader, criterion, ep)
ニューラルネットワークの定義
以下の部分が、ニューラルネットワークを定義している部分になります。ニューラルネットワークを表すクラスは nn.Moduleを継承して書きます。
class Net(nn.Module):
"""Net Module
MNISTを学習するためのネットワーク
"""
def __init__(self):
"""
__init__ではNetworkの初期化をする。
どのようなレイヤを使うのかを定義する
"""
super(Net, self).__init__() # 初期化
self.base_net = nn.Sequential( # base_netは特徴分析用のネットワーク
nn.Conv2d(1, 20, 5, 1), # Conv2Dレイヤ
nn.ReLU(), # ReLU活性化関数
nn.MaxPool2d(2), # maxpoolingレイヤ
nn.Conv2d(20, 40, 5, 1), # Conv2Dレイヤ
nn.ReLU() # ReLU活性化関数
)
self.classfier = nn.Sequential( # classifierは分類用のネットワーク
nn.Linear(40*8*8, 100), # Linearレイヤ、 40*8*8ユニットの入力を受けて、 100ユニットを出力する
nn.ReLU(), # ReLU活性化関数
nn.Linear(100, 10), # Linearレイヤ MNISTは 10この数字を当てる問題なので出力は10ユニット
nn.LogSoftmax() # LogSoftmaxレイヤ
)
def forward(self, x):
"""
forwardでは、どのようにデータをネットワークに通すかを書く
"""
x = self.base_net(x) # base_netへ特徴を通す
x = x.view(-1, 40*8*8) # base_netと classifierでは入力テンソルの形が違うので変形する
x = self.classfier(x) # classifierへ通す
return x
__init__()メソッドにネットワークに必要なレイヤを定義します。今回は、self.base_netとself.classifierという2つのネットワークを連結したネットワークとしました。それぞれ、nn.Sequentialでレイヤを追加しています。ここでは、レイヤの種類については後述します。ここでは、こんなふうに作るという事がわかればそれで十分です。
forward()メソッドには、データをどのようにネットワークに通すのかを書きます。ここでは、引数として与えられた xというテンソルをネットワークに通していきます。まず、xをself.base_netにとおします。つぎに、self.classifierに通すのですが、その前に、一度テンソルのshapeを変えています。これについてもあとで説明しますので心配しないでください。shapeを変えたあとは、self.classiferに渡します。
train関数
学習を動かす train関数は次のようになります。まず、model.train()でニューラルネットワークを学習モードにします。次にforループで学習データをbatchに取り出します。batchには、dataとtargetという二つのデータが入っています。今回、dataは学習用の画像で、targetはその画像が示す数字です。optimzer.zero_grad()では、一つ前の学習に使った勾配の情報を消去します。pred = model(dataでdataをニューラルネットワークにとおした出力を取り出します。loss = criterion(pred, target)では、ニューラルネットワークの出力predと正解データtargetの誤差を計算しています。loss.backward()で、この誤差の勾配を計算します。optimizer.step()では、計算した勾配をもとに、学習を行います。train_loss += loss.item()は学習の状況を確認するために計算した誤差の大きさを記録しています。
def train(model, device, train_loader, optimizer, criterion, epoch):
"""
学習用の関数
"""
model.train() # Networkを学習モードにする
train_loss = 0
for batch in tqdm(train_loader):
data, target = batch # batchからデータとターゲットを取り出す
data, target = data.to(device), target.to(device) # デバイスへデータを転送
optimizer.zero_grad() # 勾配の情報をゼロにリセット
pred = model(data) # ネットワークにデータを入れる
loss = criterion(pred, target) # 損失を計算
loss.backward() # 勾配を計算
optimizer.step() # ネットワークを更新
train_loss += loss.item() # 損失を記録
print(f"Epoch {epoch}: Train loss {train_loss / len(train_loader)}")
test関数
test関数では学習したネットワークの評価を行います。train関数とやっている事はほぼ変わりません。ちがうのは以下の部分です。まず、評価では学習を行わないためoptimizerを用いません。評価中は、model.eavl()で評価もモードにします。また、with torch.no_grad():で評価の間で勾配の情報を用いない事を宣言します。このようにすると、消費メモリ量や計算量を削減できます。correct += pred.argmax(dim=1).eq(target).sum().item()で予測結果と正解データの数字が一致しているかを記録しています。
def test(model, device, test_loader, criterion, epoch):
"""
評価用の関数
評価用の関数では、学習と違い、optimizerが不要
"""
model.eval() # ネットワークを評価モードに
test_loss = 0
correct = 0
for batch in tqdm(test_loader):
with torch.no_grad():
data, target = batch
data, target = data.to(device), target.to(device)
pred = model(data)
loss = criterion(pred, target)
test_loss += loss.item()
correct += pred.argmax(dim=1).eq(target).sum().item() # 正解率を計算
print(f"Epoch {epoch}: Test loss {test_loss / len(test_loader)}, Accuracy {100. * correct / len(test_loader.dataset)} %")